
Managing duplication is a licensed service which automatically identifies possible duplicate records in your account and helps you to merge them.
This tool automatically identifies possible duplicates for you based on set rules, which you can then choose to merge. Note that this service goes beyond the standard “merging” tool which you can do via Lookup supporters.
What is a duplicate record?
Within the software, a ‘record’ is identified by the email address associated with it – this is in effect used as the unique identifier for each supporter/constituent record within your database. A duplicate is an instance where multiple records exist for what is seemingly the same individual. Such duplicates can occur for a multitude of reasons, including mis-typed email addresses upon page submission, old email addresses that are no longer in use and so on. De-duplication is a way of tidying up your data, so it only contains records that are actually valid, and disposing of the records that are old or invalid, but retaining any transactions associated with those records.
Getting started
If you have added this feature to your license, you can access it from the ‘Data and Reports’ tab in the dashboard. Select Data and Reports > Manage duplication and you will be taken to the Duplicate management interface. Here you will see a short overview of the total number of supporters that make up your database, as well as the total numbers of duplicates that have already been identified by the service. On the first run, this number will of course be 0.
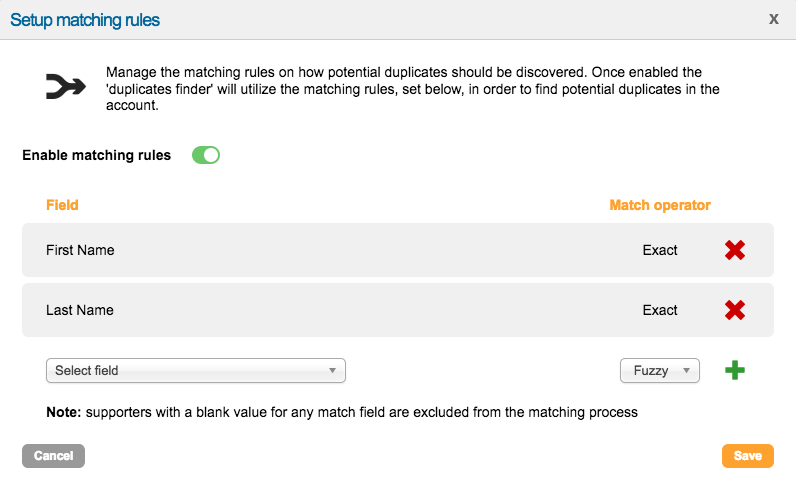
Before any duplicates can be identified, you will need to add some instructions in the form of rules that will tell the service what to look for when it runs. Rules can be set for any non-transactional fields that form your Account data structure, such as First Name, Last Name, Postcode, Country etc.

Click on ‘Set up rules’ under ‘Matching rules’ to start setting up the service to identify potential duplicate records. Once you have turned on the ‘Enable matching rules’ switch, you will need to decide which fields in your account’s data structure will be checked to identify individuals, then decide whether you want this to be an exact match or a ‘fuzzy’ match. You can add multiple fields, which will always match with an ‘AND’ logic (which means they have to obey every rule to be a match). Any supporter with a blank value in any of the match fields will always be ignored, and will not constitute a match.
Working with potential duplicates
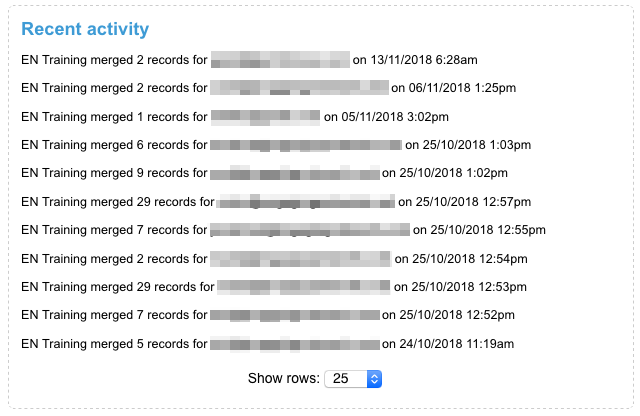
The service will run every night to identify more potential duplicate records in your account. A maximum of 1000 newly identified records will be added to the queue on each run. After the first run, you should have a few matches and can begin processing them. Any user with access to this function is able to process duplicates, and you will see an overview of the most recent activity on the Duplicate management landing page. The overview includes information about which of your users processed a duplicate, as well as which record was affected.
Start processing matches
Once a number of duplicates have been identified, you can click on 

![]()

The number of potential duplicates will be displayed in the ‘Potential Dups’ column for each record. If this number is high, you will likely encounter situations were records have already been dealt with as you process your way through the list. Any records that have already been deleted by a previous merge operation will still appear in the queue as you move through it. When these records are encountered in the workflow it will result in an ’empty’ display which simply displays two column headers: ‘Field’ and ‘Record to save’.

Looking at a record with potential duplicates, the ‘Initial match’ will be the record we are currently working on. Each potential match will be displayed as a separate column, but matches are not returned in any particular order, so review each potential match carefully before you decide which action to take.
You can tick 
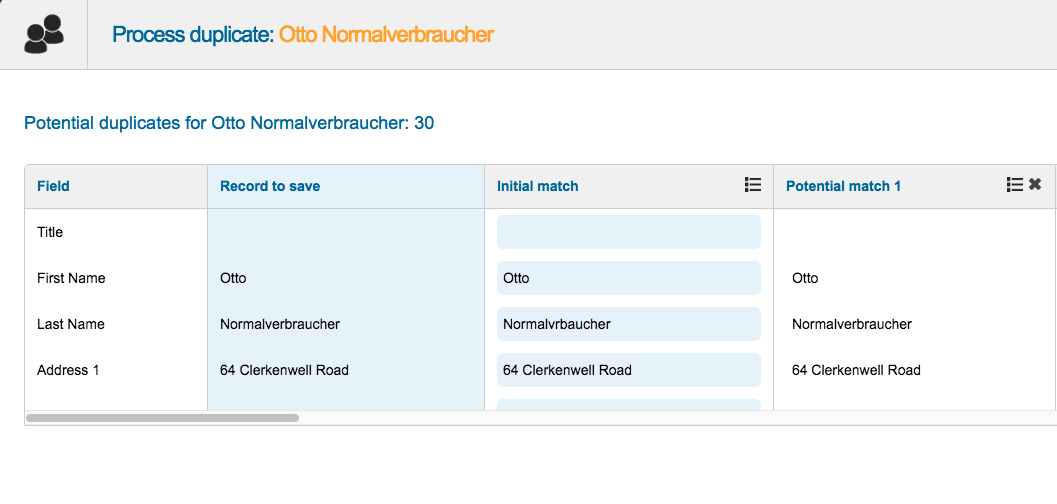
For each ‘Potential match’ record, you will have two action icons available. These are be used to either select all fields for that record, or to remove a record from the merging process. To select all fields for a potential match you can use the ‘Select all’ icon. 
Note that you can only select one value per field from all the potential matches, so if you find a better value for ‘First Name’ in a potential match and click on that, the First Name value in the ‘Initial match’ record will be de-selected and the new value added to the ‘Record to save’. The selected values for any field will be highlighted with a different background color.

Note : When reviewing potential matches, the ‘Email Address’ field may have an alert icon 
Completing a merge
Once you are satisfied that you have made the correct selections of field values from the available matches, and made sure that you have excluded any records that should not be part of the merging operation, you should have complete set of values going to the ‘Record to save’.
You can now click on ‘Merge’. You will be asked to confirm the operation. The process will delete any duplicate records who remain in the list of ‘Potential matches’. Any values you have selected from the duplicate records will be stored to the ‘Record to save’, and any transactions attributed to the duplicate records also will be re-assigned to the record listed in the ‘Record to save’ column.
Changing matching rules
It is possible to modify the rules used to match potential duplicates by clicking on 
If you are making changes to the rules after de-duplication has run for a while, it may be advisable to clear the current possible duplicates list. This will mean that you will be able to start again, hopefully with a better and shorter list of possible matches. Clearing will start from 0, and the de-duplication job will look through the first 1000 supporters on the next nightly run, and the following 1000 on the next run and so on until all potential matches have been identified.
FAQs
Q. How does the tool find new duplicates?
The tool looks for 1,000 new duplications each night, and then stops once it has found them all.
Q. How does the fuzzy search work?
Auto fuzziness based on Levenshtein Edit Distance, which is the number of changes to change one word into another.
Q. If I change the matching rules without clearing the queue, does it start from scratch?
It will remove supporters already in the queue. If the rules change quite drastically, it’s best to start the search over again by clearing what’s been processed.
Q. Does it merge transactions as well?
Yes. Transactions are merged but it’s not an immediate process.